代理模型辅助的演化计算
本文是对 Surrogate-assisted evolutionary computation: Recent advances and future challenges 这篇综述的阅读笔记。 这是一篇发表于2011年的关于在演化计算中如何应用辅助模型的综述。
前言
绝大部分的演化计算都假设存在一个可以为每一个个体提供 fitness value 的手段,或是模拟,或是实验,或是一个显式的 fitness function。 但是有的时候,这个 fitness 的评估是非平凡的,例如当模拟或实验需要消耗大量成本。 此时通过使用代理模型的演化计算方法来减少昂贵问题上使用演化计算时间成本。
代理模型往往和真实的 fitness function 一起使用,以防演化计算被误引入代理模型提供的错误最优。 当问题越高维度,代理模型的构建难度就越大。
代理模型的策略
No analytical fitness function exists for accurately evaluating the fitness of a candidate solution. Instead, there are only more accurate and less accurate fitness estimation methods, which often trade off accuracy with computational costs.
使用代理模型也需要权衡模型的效率和保真度。 最初,一部分工作完全依赖代理模型进行演化搜索,但是代理模型引入的可能并不存在的最优会带来严重的问题。 代理模型几乎可以用在所有的演化计算步骤中来剔除差的结果,并且减少随机性:population initialization, cross-over, mutation, local search and fitness evaluations。
根据代理模型的使用对象进行不同,可以将代理模型方法分类可以分为以下三类:
- Generalization based:
- surrogates are used for fitness evaluations in some of the generations, while in the rest of the generations, the real fitness function is used
- Individual based:
- the real-fitness function is used for fitness evaluations for some of the individuals in a generation
- Population based:
- more than one subpopulation co-evolves, each using its own surrogate for fitness evaluations. Migration of individuals from one sub-population to another is allowed.
单代理模型
我们假设与真实 fitness 函数交互费时,希望尽可能减少与真实函数交互。 那么关键的问题就在于如何确定哪个个体是应该被重新评估的。 我们需要考虑到以下三个方面。
1. 选取重评估样本的标准
不得不说这些选取的方式和主动学习极度相似。 选取具有以下特征的样本评估:
- potentially have a good fitness value
- representative
- large degree of uncertainty in approximation
- fitness landscape around these solutions has not been well explored
- improve the approximation accuracy of the surrogate,
如何描述或者估计这种不确定性或者错误呢?
- uncertainty is roughly set to be inversely proportional to the average distance to the closest data samples
- estimating the variance of the individual estimates given by an ensemble of surrogates
2. 如何评估代理模型的好坏
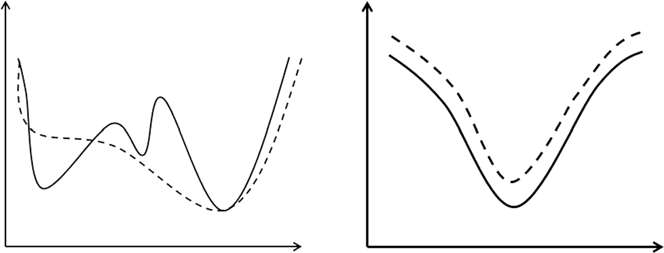
首先代理模型并不是需要严格和 fitness function 相同才可以发挥作用,在存在较大的预测错误时同样可以起到作用,如下图所示。
一些常用的度量:
- mean squared error between the individual’s real fitness value and the predicted fitness
- the number of individuals that have been selected correctly using the surrogate
- the rank of the selected individuals, calculated based on the real fitness function.
- rank correlation: measure for the monotonic relation between the ranks of two variables
- continuous correlation between the surrogate and the original fitness function.
3. 提升预测的准确性
- 神经网络的正则化
- 随着搜索更新模型
- 建立一个地位的搜索空间
- 评估时利用生成的中间数据
多代理模型
模型类别可能不同,模型保真度(fidelity)可能不同。 此处根据对 fidelity 的掌控把多代理模型分为两类,同质(homogeneous)和异质(heterogeneous)多代理模型。
By homogeneous multiple surrogates, the fidelity of the surrogates are not explicitly controlled, even if different types of surrogates are used.
On the contrary, heterogeneous surrogates vary in their fidelity due to an explicit control in model complexity or training data.
- 同质(homogeneous)多代理模型
- 多个模型可以提升预测质量,也可以帮助识别较大的预测错误。
- 其经验有效性在多篇工作中得到证实。
- 异质(heterogeneous)多代理模型
- 其实是组合了一些列不同粒度的代理模型。
- 这类工作提出的背景也是训练不同粒度的代理模型会有不同的成本,粒度越低成本越低。
在昂贵问题之外更多的考虑
- Surrogates in interactive evolutionary computation
- Surrogated-assisted evolution for solving dynamic optimization
- Surrogates for robust optimization
- Surrogates for constrained optimization
实际应用
代理模型的方法更多的是应用驱动。
One intensively researched area is surrogate-assisted design optimization, such as turbine blades, airfoils, forging, vehicle crash tests, multi-processor systems-on-chip design and injection systems. Other applications include drug design, protein design, hydroinformatics and evolutionary robotics.
未来挑战
- Theoretic work
- Multi-level, multi-fidelity heterogeneous surrogates
- Surrogate-assisted combinatorial optimization
- Surrogate-assisted dynamic optimization
- Rigorous benchmarking and test problems