强化学习 & 模仿学习基础知识
总是会看到强化学习及模仿学习的内容,每次看完都会忘记,此处把之前的小笔记总结一下。
基本术语 Terminologies
以下术语在强化学习和模仿学习中都经常见到。
- agent: the intelligent individual
- environment: The agent is acting in an environment.
- state: Current condition. The agent can stay in one of many states of the environment
- action: The agent chooses to take one of many actions under the certain states.
- reward: Once an action is taken, the environment delivers a reward as feedback.
- policy: Agents’ behavior.(s => a) The agent’s policy π provides the guideline on what is the optimal action to take in a certain state with the goal to maximize the total rewards.
- value: (s => value) Each state is associated with a value function V(s) predicting the expected amount of future rewards we are able to receive in this state by acting the corresponding policy.
- state-value of a state s is the expected return if we are in this state at time t.
- action-value (“Q-value”; Q as “Quality” I believe?) of a state-action pair is expected return if we are in this state at time t and take action a.
- A-value: The difference between action-value and state-value is the action advantage function (“A-value”):
- model: Transition and reward. (s,a => s’ & r) How the environment reacts to certain actions (we may or may not know).
强化学习
1. 马尔科夫决策过程
In more formal terms, almost all the RL problems can be framed as Markov Decision Processes (MDPs). All states in MDP has “Markov” property, referring to the fact that the future only depends on the current state, not the history. The goal is to react on each state to maximize the total reward.

如果所有 MDP 成分都已知,我们便可以较容易的训练出来一个 agent。 但是现实情况是很多时候,我们的 agent 对 transition function 和 reward function 一无所知,所有的信息都来自于同环境的交互。
1.1. 强化学习方法分类
- 以是否对环境建模分类:
- Doesn’t model the environment:
- Model-free RL: Doesn’t need to know the transition function (“model”), neither the real function nor a learned function.
- Model the environment:
- Model-based RL: Need to know the transition function (“model”), either the real function or a learned function.
- Inverse reinforcement learning: Need to learn a value function for a state. (Imitation learning)
- Doesn’t model the environment:
- 以行动策略和评估策略是否相同分类:
- On-policy: Use the deterministic outcomes or samples from the target policy to train the algorithm. 行动策略和评估策略相同
- Off-policy: Training on a distribution of transitions or episodes produced by a different behavior policy rather than that produced by the target policy. 行动策略和评估策略不同
1.2. 对价值函数进行评估和分解
强化学习的目标是可以使最终价值最大化,所以需要对其进行评估。
Bellman equations refer to a set of equations that decompose the value function into the immediate reward plus the discounted future values.
2. Common Approaches

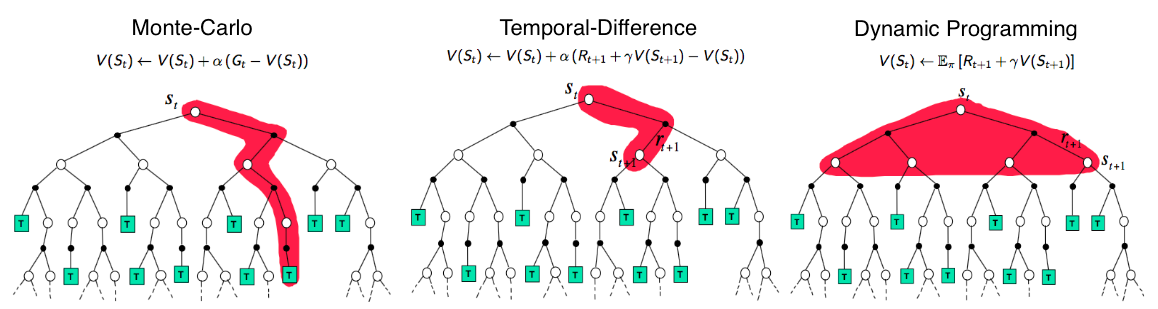
2.1. Dynamic Programming
When the model is fully known, following Bellman equations, we can use Dynamic Programming (DP) to iteratively evaluate value functions and improve policy. The policy would greedy based on the Q-value. Iteratively update the state value and the Q-value.
Generalized Policy Iteration (GPI) adaptive dynamic process
2.2. Monte-Carlo Methods
Model-free method. It learns from episodes of raw experience without modeling the environmental dynamics and computes the observed mean return as an approximation of the expected return
2.3. Temporal-Difference Learning
TD Learning is model-free and learns from episodes of experience. However, TD learning can learn from incomplete episodes and hence we don’t need to track the episode up to termination.
主要思想是将效用估计朝着理想均衡方向调整:
- TD调整一个状态与已观察到的后继状态相一致
- ADP调整一个状态与可能出现的的后继状态相一致
- TD可视为对ADP的一个粗略有效的一阶近似
To learn optimal policy:
- SARSA: On-Policy TD control
- “SARSA” refers to the procedure for updating the Q-value.
- Same routine of GPI.
- In each step of SARSA, we need to choose the next action according to the current policy.
- Q-Learning: Off-policy TD control
- The key difference from SARSA is that Q-learning does not follow the current policy to pick the second action (off-policy).
- Q-learning may suffer from instability and divergence when combined with an nonlinear Q-value function approximation
- Deep Q-Network
- It quickly becomes computationally infeasible to memorize Q-table when the state and action space are large.
- Use functions (i.e. a machine learning model) to approximate Q values and this is called function approximation.
- greatly improve and stabilize the training procedure of Q-learning by two innovative mechanisms:
- Experience Replay: improves data efficiency, removes correlations in the observation sequences, and smooths over changes in the data distribution.
- Periodically Updated Target: only periodically updated, overcomes the short-term oscillations
2.4. Combining TD and MC Learning
In TD learning, we only trace one step further down the action chain when calculating the TD target. One can easily extend it to take multiple steps to estimate the return.
2.5. Policy Gradient
All the methods we have introduced above aim to learn the state/action value function and then to select actions accordingly. Policy Gradient methods instead learn the policy directly with a parameterized function.
- Measure the quality of a policy with the policy score function.
- Use policy gradient ascent to find the best parameter that improves the policy.
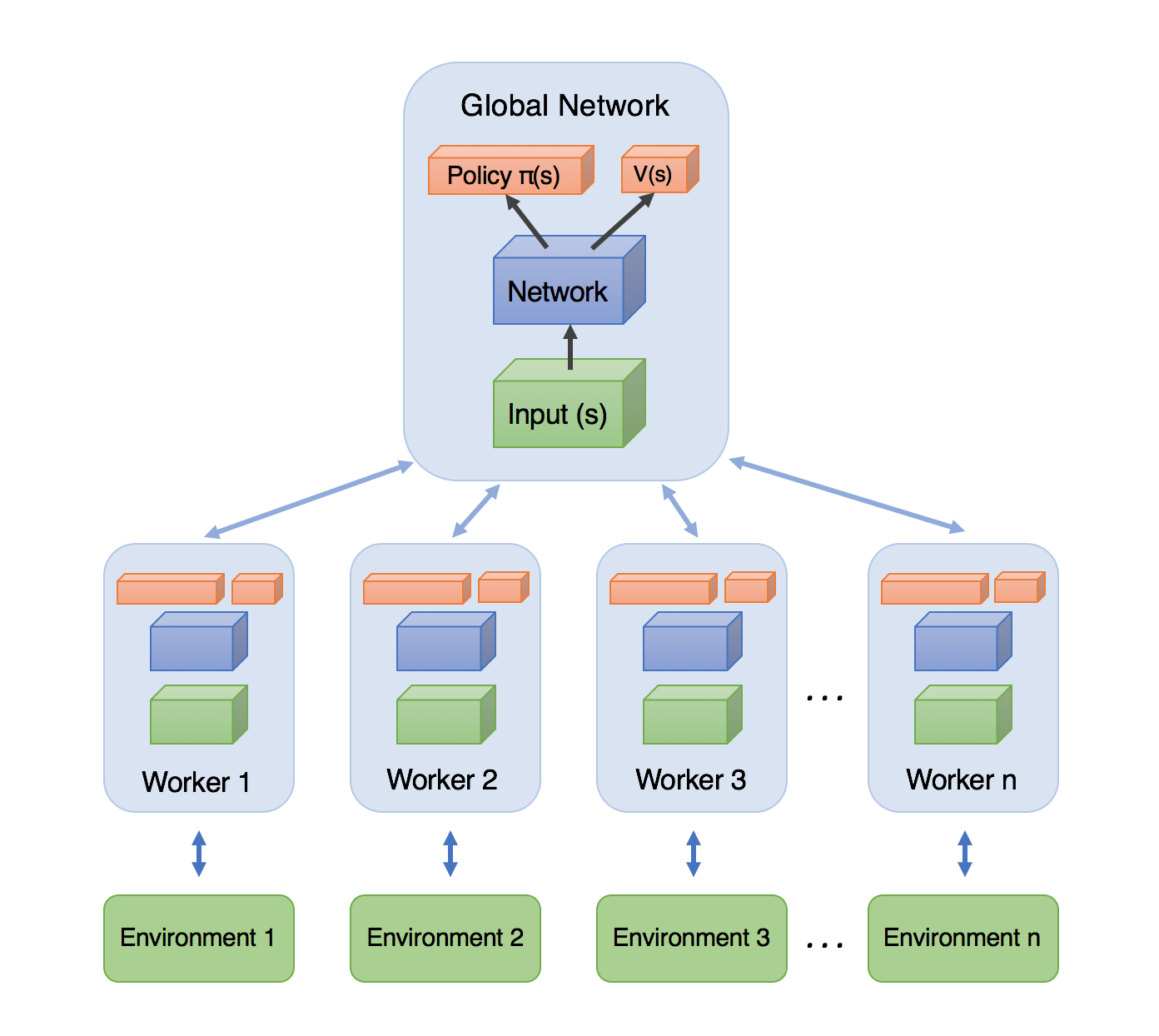
2.6. Asynchronous Advantage Actor-Critic (A3C)
- Asynchronous: Several agents are trained in it’s own copy of the environment and the model form these agent’s are gathered in a master agent. The reason behind this idea, is that the experience of each agent is independent of the experience of the others. In this way the overall experience available for training becomes more diverse.
- Advantage: Similarly to PG where the update rule used the dicounted returns from a set of experiences in order to tell the agent which actions were “good” or “bad”.
- Actor-critic: combines the benefits of both approaches from policy-iteration method as PG and value-iteration method as Q-learning (See below). The network will estimate both a value function V(s) (how good a certain state is to be in) and a policy π(s). Agent uses the value estimate (the critic) to update the policy (the actor) more intelligently than traditional policy gradient methods.
3. Known Problems
- Exploration-Exploitation Dilemma
- Deadly Triad Issue: off-policy, nonlinear function approximation, and bootstrapping are combined in one RL algorithm, the training could be unstable and hard to converge.
模仿学习
1. 背景
Background:
- Given: demonstrations or demonstrator
- Goal: train a policy to mimic demonstrations
Intuition:
- 人们并不总是知道执行某项任务所获得的报酬
- 但是人们可能会知道“做什么是正确的事情(最佳策略)
Rollout: sequentially execute on an initial state
- Produce trajectory
2. 模仿学习分类
- Behavior cloning
- Direct policy learning (multiple step BC)
- Inverse reinforcement learning (assume learning R is statistically easier)


2.1. Behavioral Cloning (simplest Imitation Learning setting)
Treat experts’ states-actions pairs i.i.d and as training example use supervised learning (from state to action). Distribution provided exogenously.
When to use BC?

2.2. Direct Policy Learning
Learning reduction: Reduce “harder” learning problem to “easier” one
Idea:
- Construct a sequence of distributions or sequence of supervised learning problems.
- Query interactive oracle about the state and construct a loss function according to our action and expert action on this state.


2.3. Inverse reinforcement learning
Inverse RL指我们需要对环境的reward进行建模。 RL与IRL的对比如下图所示:

In a traditional RL setting, the goal is to learn a decision process to produce behavior that maximizes some predefined reward function. Inverse reinforcement learning (IRL), flips the problem and instead attempts to extract the reward function from the observed behavior of an agent. IRL seeks the reward functions that ‘explains’ the demonstrations.
此时同样存在是否依赖 transition function 的情况

References
- https://en.wikipedia.org/wiki/Reinforcement_learning
- https://medium.com/@SmartLabAI/reinforcement-learning-algorithms-an-intuitive-overview-904e2dff5bbc
- https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html
- 人工智能:一种现代的方法
- https://sites.google.com/view/icml2018-imitation-learning/