Prompt 学习记录
在自然语言处理中有一个叫做 prompt 的新范式最近较火,其背景是在少标记的场景下学习。 本文主要内容都是从 Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing 这篇综述中提取。 仅涵盖本人认为最需要被科普的内容。
背景
当前在自然语言处理中主要存在以下范式,其中由 a 到 d 基本按照时间顺序出现。 总的来说,目前为止经历了两个 sea changes(重大变化)。
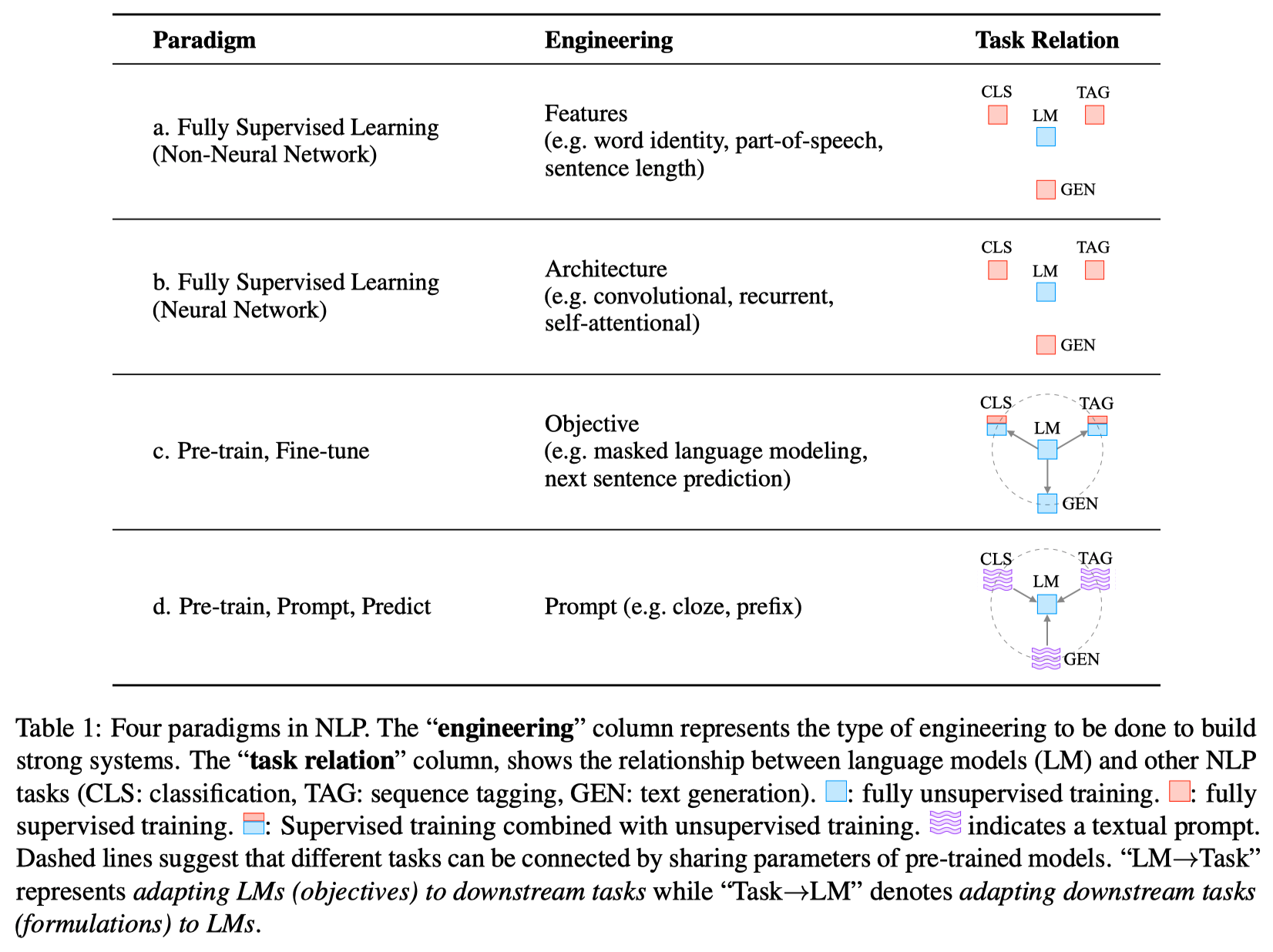
在2017年以前,主要以完全监督学习为主(a和b范式)。 研究的主要内容在于特征提取(传统模型),结构构建(深度模型)。 但是在2017年之后,经历了第一个重大变化,完全监督的旧范式的使用不断在缩小,预训练及微调(c范式)开始流行。 在当前时间节点,2021年,正在经历第二个重大变化。 当前对于下游任务学习并不是通过预训练及微调中的 objective engineering,而是通过 prompt(提示)来实现。
这里举一个 prompt 的例子。
When recognizing the emotion of a social media post, “I missed the bus today.”, we may continue with a prompt “I felt so __”, and ask the LM to fill the blank with an emotion-bearing word.
Or if we choose the prompt “English: I missed the bus today. French: __”), an LM may be able to fill in the blank with a French translation.
通过这种选取合适的 prompt 的方法,预训练的 language model(LM)可以用来预测合适的输出,有时甚至不需要 task-specific 的训练。
Prompt 的正式表述
基于 prompt 的方法尝试规避无法获得大规模数据的问题,直接对样本 的概率 进行建模,之后再用这个概率来预测。 以下是一些基于 prompt 的方法中的术语。
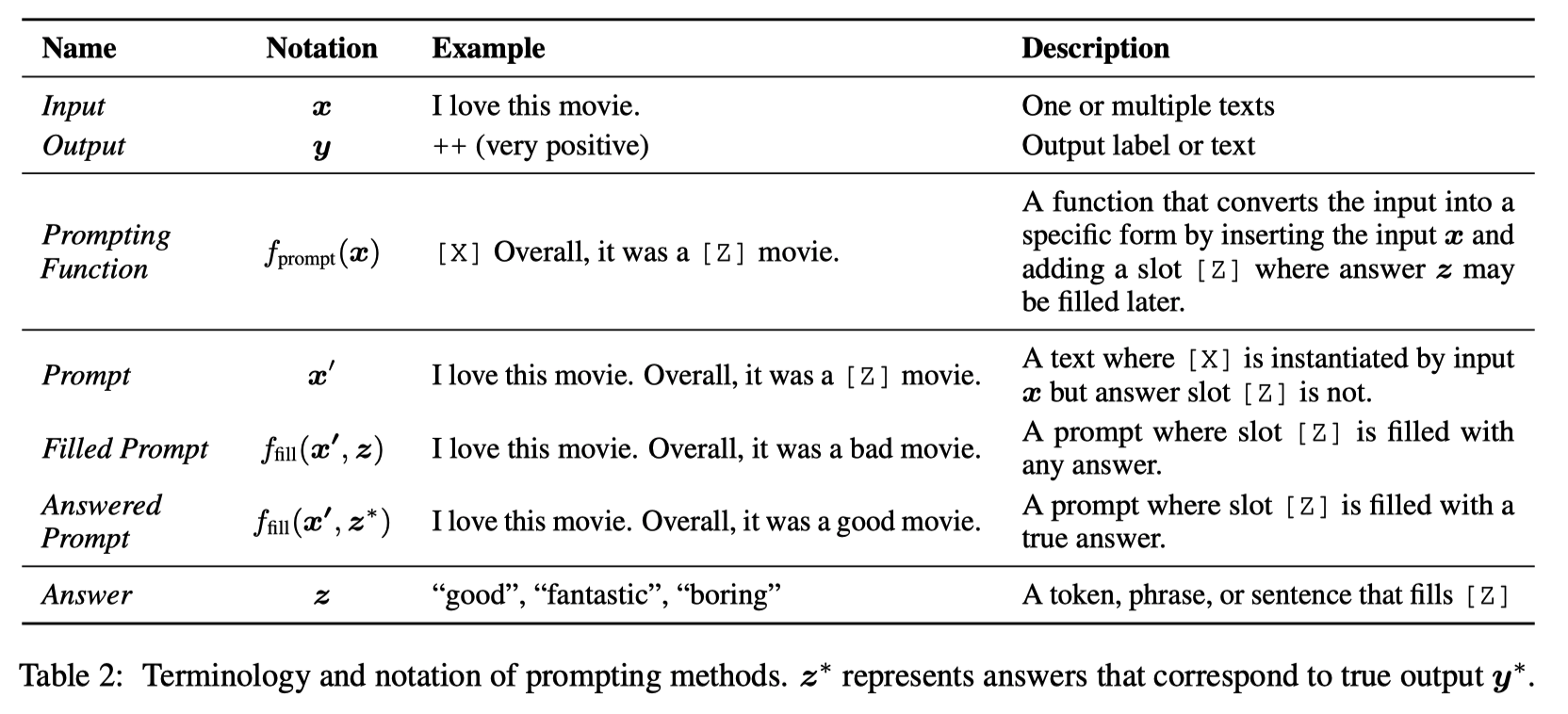
通常来说,prompt 的方法预测高质量的输出 有三步。
- Prompt Addition:通过模版,将原始语句转化为 Prompt,含有空白等待填入。
- Answer Search:在候选集中,选取 answer prompt 。
- Answer Mapping:将高分的回答 和高分的输出 对应起来。
设计 Prompt 时需要考虑的具体问题
这里一般来说存在以下5个需要具体考虑的问题:
- 如何选择预训练模型
- 选择何种 Prompt 来作为 Prompting funtion(模版)。
- 设计候选集,可能同时还需要考虑与输出的映射。
- 对简单框架的扩展以提高表现和适用性。
- 训练参数的策略
此处不一一展开,可以到综述中寻找具体的部分。
Prompt 的应用和挑战
这篇综述也详尽的展开了当前 Prompt 的应用和挑战。 这里只简单记录不做展开。
应用方面,几乎涉及了 NLP 的方方面面,集中于以下几大类:Knowledge Probing、Classification-based Tasks、Information Extraction、“Reasoning” in NLP、Question Answering、Text Generation、Automatic Evaluation of Text Generation、Multi-modal Learning、Meta-Applications。
挑战方面,主要集中于以下几个大类:Prompt Design、Answer Engineering、Selection of Tuning Strategy、Multiple Prompt Learning、Selection of Pre-trained Models、Theoretical and Empirical Analysis of Prompting、Transferability of Prompts、Combination of Different Paradigms、Calibration of Prompting Methods。
相关资料
- Pretrain, Prompt, Predict: A New Paradigm for NLP
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- PromptPapers
对这个范式的看法
Prompt 方法归根结底还是面向标记数据缺乏这一老生常谈的问题。
从二十多年前的经典方法开始,大家就在对这一问题展开研究。 从模型角度入手似乎还是比较少见,主要还是在学习范式的角度上进行研究。 从最开始的监督学习,到半监督学习,还有迁移学习,都是致力于使用有限的标记来最大化任务表现。 近几年这种半监督,或者说自(无)监督的方法已经极大程度上融进了目前机器学习的框架中。 有时作为一种特征提取器而存在,有时作为一种正则化而存在。 从这一角度来看,当前的几种范式,都是在探讨如何最大化利用未标记样本,Prompt 也不例外。
对于 Prompt 而言
在我来看 Prompt 的定位应该是一种较为成熟的广泛适用于文本的自监督学习方法。 自监督学习关键在于定义一种可以自己知道正确答案的任务,用此任务来训练,以得到对该任务的较好表现,同时也可以获取质量相对较好的特征以适用于下游任务。
当前的预训练模型大多都是由 mask 这类操作来自监督训练。 所以在预训练模型上学习的填空能力是可以很好的用于 Prompt 定义的填空题。 由于这种填词题在训练的时候已经见过,不像很多下游任务还需要知道之前没见过的标签,所以预训练模型在寻找 answered prompt 时可以 zero-shot 或者 few-shot。
总的来说,这种范式设计了一种能“引诱”模型输出之前在大量样本中学到的统计(/逻辑/推断)数据。 个人觉得还是蛮有意思,或许可以用来对模型进行解释。
对于自己主动学习的研究而言
主动学习和这些范式其实不太相同,上述半监督自监督学习主要考虑如何利用未标记样本,而主动学习是在探讨如何最大化利用有限的标记成本来选取最有价值的样本。 其已假设更重要的样本能学出来相对随机选取的样本更好的模型。
在当前无监督自监督学习表现如此之好的情况下,单纯使用主动学习得到的标记样本意义似乎不大。 因为单纯选取少量重要的标记样本可能仍旧难以与大量未标记样本上的自监督匹敌。 这就是那两篇主动学习劝退文里面指出的问题。 所以说个人认为主动学习中,尤其是模型的训练部分,为了最大化效用,应该是一定是要使用未标记样本的。
主动学习中存在标记,那么必然是一个下游任务。 那么具体如何结合少量标记样本和大量未标记样本来训练,就是其他那几种范式。 在其他范式上学到的特征提取器上对于下游进行微调,可能才是主动学习最好的实施方法。 具体如何微调,又是一个研究了很久的问题。
所以这种无机的结合可能才是主动学习的实际场景。