Contrastive Learning 学习记录
本文最后更新于:3 年前
之前总是会断断续续看到一些自监督学习的工作/想法。 同时也总是看到对比学习这个词,不明所以,所以对此进行一个简单的学习。 本文可以看作对《对比学习(Contrastive Learning):研究进展精要》这篇知乎文章的阅读笔记。
背景
自监督学习有着从无标记样本中学习表征的能力。 比较出名的是自然语言模型 Bert 的预训练。 对比学习是一种自监督学习的方式,主要用在图像领域。
目前,对比学习貌似处于无明确定义、有指导原则的状态,它的指导原则是:通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
对比学习的关键点:
- 如何构造相似实例,以及不相似实例
- 如何构造能够遵循上述指导原则的表示学习模型结构
- 以及如何防止模型坍塌(Model Collapse)
目前的对比学习方法分类
- 基于负例的对比学习方法
- 基于对比聚类的方法
- 基于不对称网络结构的方法
- 基于冗余消除损失函数的方法
几种分类
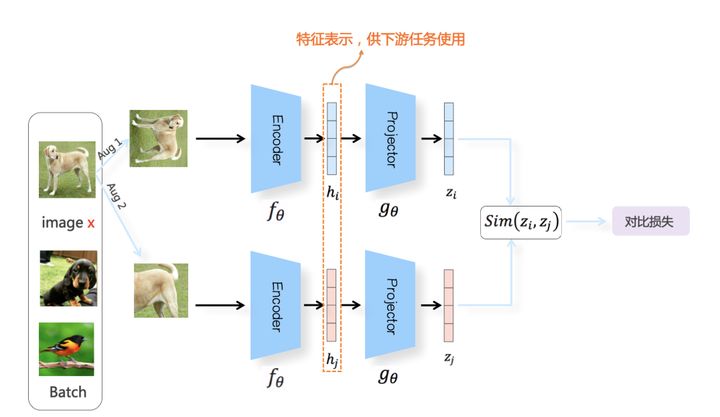
基于负例:SimCLR
首先我们需要构建正例和负例。 负例的话,同一个 batch 的其他样本可以当作此样本的负例。 正例的话一般通过图像增强来实现,如下图所示。

模型层面,SimCLR 具有上下两个 Branch,通过学到的表征来计算 Similarity。 需要注意的是,相似度计算需要正则化。
其中的相似度损失使用 infoNCE,其中为温度参数:
温度接近0的时候,该损失基本退化为 Triplet(对很相似样本的区分)。
为什么 SimCLR 投影操作要做两次非线性变换,而不是直接在Encoder后,只经过一次变换?
- 在 Moco 中并没有 Projector,在 SimCLR 加入 projector 后效果提升明显。
- SimCLR 论文中表示,Encoder后的特征表示,会有更多包含图像增强信息在内的细节特征,而这些细节信息经过Projector后,很多被过滤掉了。
Triplet Loss
此处对 triplet loss 做一个相关学习。 这项损失目的也是将正样本距离拉近,负样本距离拉远(但是对于一些难负样本,似乎还是主要拉近正样本)。 其形式如下:
其中 和 分别为正负样本。 Margin 是一个大于零的数,希望与正样本的距离至少比负样本的距离小一个 margin。 这种 loss 一般用于人脸识别,细粒度分类等这种训练样本差异较小的个体识别任务。
基于负例:Moco V2
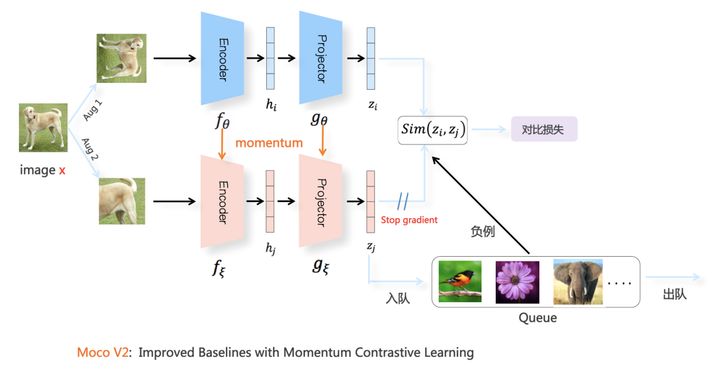
其有以下特点:
- 相比于 Moco 增加了 projector。
- 相比于 SimCLR,从整个未标记数据集选取负例。
- 上分枝反向传播,下分枝使用移动平均机制更新参数。
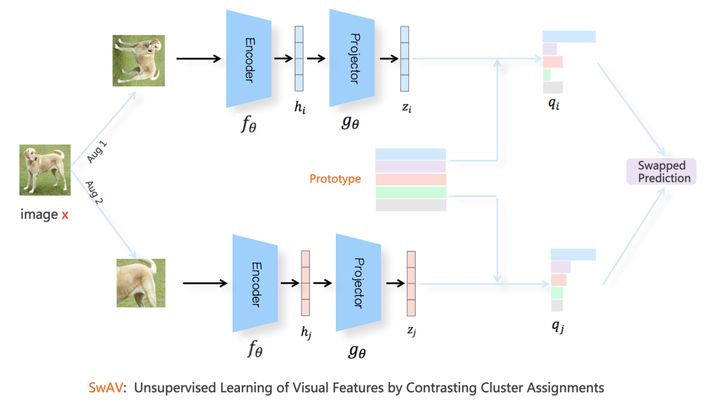
基于对比聚类:SwAV
通过上分枝预测下分枝打出的类别伪标记(由聚类得来),同时也要用下分枝预测上分枝。 具体损失函数采用 和聚类 Prototype 中每个类中心向量的交叉熵表示。
基于不对称结构:BYOL
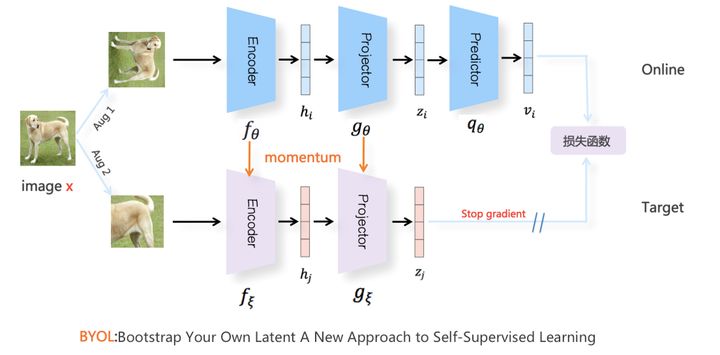
Target 分枝结构类似 Moco V2对应下分枝的 Moving Average 动量更新方式。 Predictor 的存在保证了模型不坍缩(具体为何没有定论)。
基于冗余消除:Barlow Twins
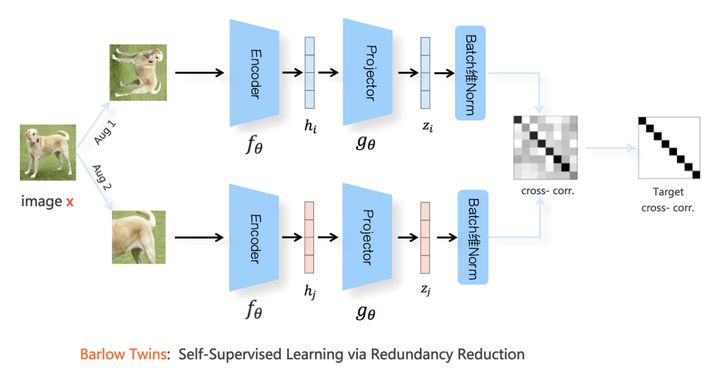
Barlow Twins 并没有去除向量的长度因素,它在Batch维度,对 Aug1 和 Aug2 里的正例分别做了类似 BN 的正则。 之后,顺着 Batch 维,对 Aug1 和 Aug2 两个正例表示矩阵做矩阵乘法,求出两者的互相关性矩阵(cross-correlation matrix),其损失函数定义在这个互相关矩阵上。 希望互相关矩阵为对角元素为1的单位矩阵,增强元素间的独立性。
现状与展望
现状
BYOL,SwAV,DeepCluster-v2 都在 many-shot(ImageNet上学,再迁移到其他数据集) 和 few-shot 上取得了比较好的表现。 其中在 many-shot 上甚至超过有监督。 数据来源于这篇论文,“How Well Do Self-Supervised Models Transfer?”。
问题
- 数据偏置问题:ImageNet 相对于普通网上能获取的数据还是太干净了。
- 正例构建问题:除了图像遮挡不变性和颜色不变性,对于其它的常见不变性,比如视角不变性、照明不变性等,对比学习模型的效果要明显弱于监督学习。
- 对于复杂任务缺乏像素级学习能力:当下都是采用判别模型。
我的看法
其实从2019年就已经陆陆续续见过很多自监督学习的工作了,一直也没有静下心来学习一下。 这次通过对这篇介绍性博文的学习,加上之前一些自己的见闻,也算是对这个自监督学习方向有了一个粗浅的理解。
总的来说,自监督学习是希望在完全无标记的样本集中学习一个富有信息的表征。 由于无标记,所以在学习表征的过程中,我们需要创建一些辅助任务来帮助学习表征。 这些辅助任务包括但不限于:
- 某种填空(类似 bert 的预训练,图像中的补全)
- 某种相似度量(对比学习)
- etc.
所以自监督学习问题的关键其实在于如何构建这个辅助任务:
- 从当下的了解来看,判别式的方法是主流,都是通过生成正负样本来构建辅助任务。
- 在我的角度看,知乎这篇文章的分类,除了 BYOL 之外,还都是通过正负样本的判别来实现的,只是如何判别略有不同,但还是在一个范式下面。
- 这种基于判别的辅助任务其实是很简单的(同时在简单的分类问题上起到了很好的表现),但这种基于简单任务学到的表征在复杂任务上的适用性还不清楚(或许不太好,文章中提到的“像素级构建能力”)。
- 或许设计更加复杂但是可行的辅助任务,能提取到更为合适且富含信息的表征。
与其他领域的关系:
- 背景上:自监督学习的出现背景还是存在大量未标记数据,其实也是在标记数据不足这个局限性下做的尝试。
- 目的上:与其他研究领域尝试学模型不同,自监督学习的主要目的是在学表征。
总的来说,我第一次见到这类方法的时候就觉得很直观且很巧妙,经过近年的发展,它的可用性已经得到了验证,个人认为在表征学习的这个道路上,自监督学习还是比较靠谱的。 但是放到具体的下游任务上,面临标记数据的匮乏时,用主动学习选取标注才是合理之选。 或许将来的可以实用的大模型都会包含一个离线的自监督学习表征模块,和一个在线的主动学习模块。 这样既可以缓解主动学习在深度表征上的乏力,也可以高效的在表征确定的时候找到目标模型。