主动学习(Active Learning),看这一篇就够了
本文是对自己 Awesome-Active-Learning 项目的一个宣传及简要介绍,不定期更新。
An English Version Of This Post: Awesome Active Learning.
0. 写在最前
在自己对主动学习(Active Learning)的学习和研究过程中,一直断断续续收集整理了很多不同方向的文章和研究进展,日积月累,整理的内容开始完善和系统化,于是将其开源成 awesome active learning 项目。
对于该项目,我的初衷是:维护一个包含主动学习方方面面的知识库,这样研究者和工程师可以较快锁定相关工作并展开科研。 同时,也由于个人的力量有限,希望大家可以一起对主动学习的相关进展进行追踪梳理和总结。如发现遗漏或错误,或想要增补一些新的内容,欢迎大家在该项目下 pull request 或者通过邮件 ruihe.cs@gmail.com 联系我。 知识库的整体结构如下图所示,希望大家能在这个知识库项目中找到你需要的关于主动学习的一切信息。
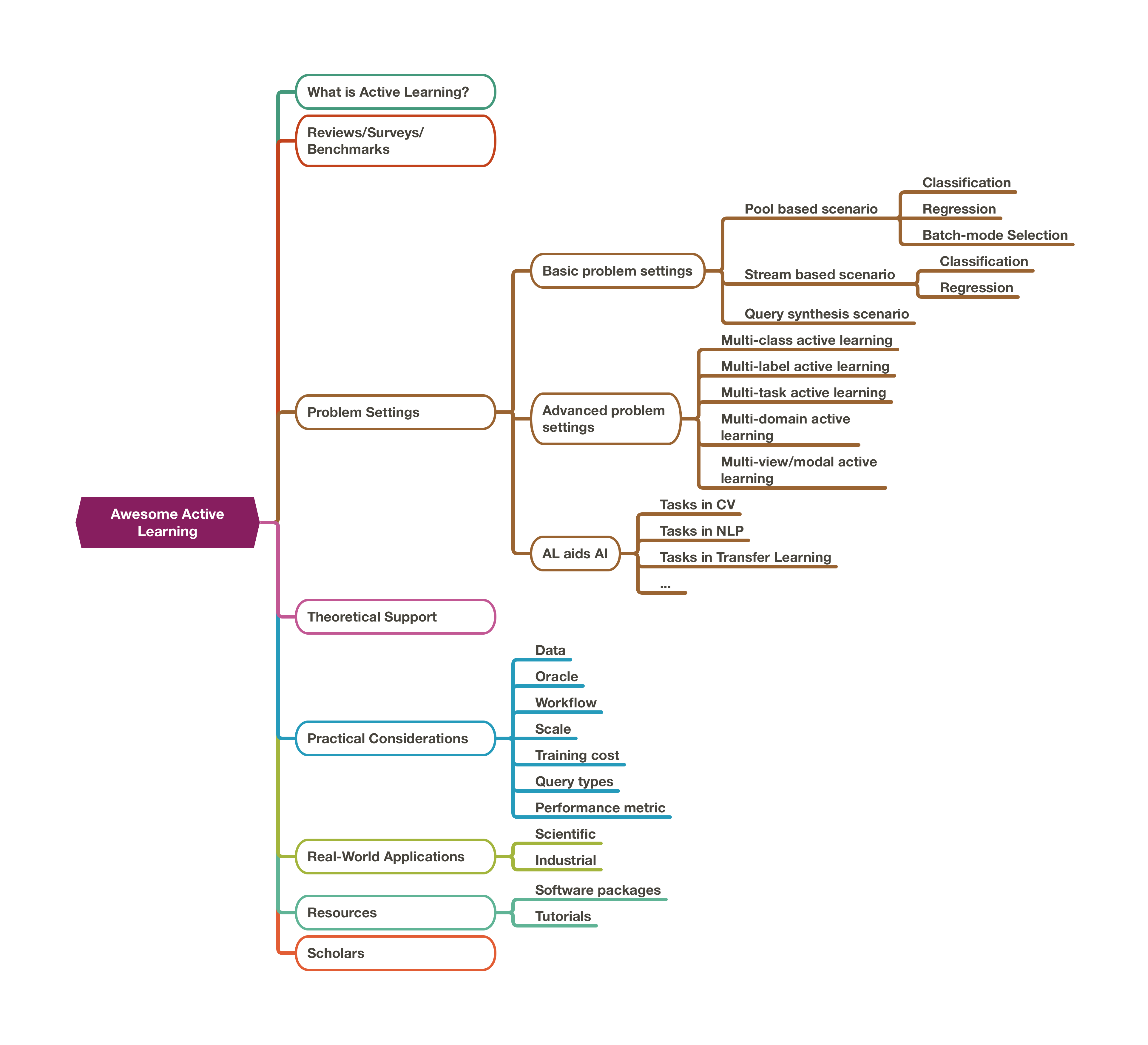
0.1. 关于本文
本文旨在对主动学习(AL)领域从一个以问题为导向的角度,展开阐述当前主动学习的研究和应用。 此处的以问题为导向包含两个方面,一是指主动学习期望解决的实际问题,二是指主动学习应用中的技术问题。 本文的重点是对这些问题进行基本的描述和文献总结,从而让大家对主动学习的适用场景有一定的认识。 一些关于理论和技术上的分类也会有所提及,但是详细内容不会在本文中展开。 此外,本文不涉及列举具体场景下具体算法的文献,若阁下对所描述的问题场景有兴趣,可以移步 github 项目并查阅相关文献列表。
0.2. 推荐阅读的 Survey/Review
作为一个相对成熟的领域,目前已有不少相关的文献综述和领域调研。 此处推荐以下两篇,其余的可以去我们的项目中查看完整的列表:
- Active Learning Literature Survey [2012]:作者为 Burr Settles。这是最著名也是相对较早的一篇调研,至今已有数千次引用,初步了解可以看这一篇。
- A Survey on Active Deep Learning: From Model-Driven to Data-Driven [2020]:较新的一篇文章,主要是在技术角度对主动学习的方法进行分类,个人认为这篇文章需要在对具体问题有足够清晰地了解之后再看,否则过早陷入对技术的纠结其实不利于对领域的认知。
0.3. 项目关键章节传送门
对于一些 AL 的关键方向,我们在此设立传送门,可以直达我们项目中的相关章节(英文版)。
- 主动学习策略分类:在 Pool-based 场景下的主要方法分类。
- AI 中的 AL:用主动学习来尝试解决 AI 各问题下的标注/查询成本昂贵问题。
- AL 的应用方向:科学研究应用和工业界应用两个方面。
- AL 使用中的实际考虑:当 AL 假设不完全成立时,或者遇到新的问题场景时如何解决。
- AL 内在的问题:AL 这种选取模式带来的不可避免的问题。
- 深度主动学习:如何在深度神经网络上使用主动学习。
1. 什么是主动学习?(若已有背景知识可跳过)
监督学习问题中,存在标记成本较为昂贵且标记难以大量获取的问题。 针对一些特定任务,只有行业专家才能为样本做上准确标记。在此问题背景下,主动学习(Active Learning, AL)尝试通过选择性的标记较少数据而训练出表现较好的模型。 下面是从 Burr 的 Survey 中选取的一个简单的例子,图©中使用主动学习策略仅选取30个样本作为训练集训练出的逻辑回归模型即可达到90%的准确率,而图(b)中随机选取的30个样本训练出的模型却相对表现较差。

从整个学习过程来看,在相同数目的标记样本下,主动学习选取的表现要好于随机选取的表现。这种可以描绘出整个学习过程的曲线也一般用于对主动学习方法进行评估。

主动学习最重要的假设是不同样本对于特定任务的重要程度不同,所以带来的表现提升也不全相同。 选取较为重要的样本可以使当前模型以较少的标记样本数得到较好的表现。 在这一过程中,主动学习的本质是对样本的重要性(/信息度/期望带来的表现等)等进行评估。 绝大多数的工作都是围绕如何评估样本来展开。
但是随着领域的发展,相关文献的增多,主动学习一词可能在强调不同的东西。总的来说,当我们谈起主动学习的时候,我们指的是:
- 从问题的角度:通过以某种主动策略构建较小训练集来减少标记成本的机器学习方式。
- 从策略的角度:以某种方式对未标记样本重要性的评估。
- 从训练的角度:一种交互式的标记、训练、评估流程。
2. 主动学习的问题/任务场景
标记成本高昂的情况在很多任务下都存在,所以主动学习的潜在应用问题还是比较广泛的。本节,我们会对大部分主动学习涉及到的问题和任务场景进行简要介绍。
2.1 基础问题场景
这里我们只讨论最基础的分类和回归问题。在这两类问题下,有着三种不同的主动学习场景:
- Pool-based scenario:此类场景通常提供一个未标记的数据池,主动学习策略在数据池中选取相应样本进行标记。
- Stream-based scenario:此类场景中,数据以数据流的形式输入,主动学习策略需要确定对当前数据进行标记还是直接用现有模型预测。
- Query synthesis scenario:此类场景较为少见,一个未标记的数据池通常也被提供,但是主动学习策略并不是在数据池中挑选样本进行查询,而是自行生成新样本进行查询。
所以我们就有了如下几个子问题:
| Pool-based | Stream-based | Query synthesis | |
|---|---|---|---|
| Classification | PB-classification (most works) | SB-classification | (rare) |
| Regression | PB-regression | SB-regression (rare) | (rare) |
其中目前据大多数的基础研究都是基于 pool-based classification,目前大多数的文献分类也是基于此问题而分类的。 此处我们以介绍清楚问题场景为主,具体对于每一个问题的具体方法,请参考: Basic AL Problem Settings
2.2 复杂问题场景
此处的复杂主要是指任务相较于简单的分类回归任务复杂。在机器学习的领域中,有不少衍生问题,包括但不限于多分类问题,多标签问题,多任务问题。作为监督学习问题,这些问题同样可以使用主动学习来缓解标记压力:
- Multi-class active learning: 在分类任务中,每个样本的标签取值可以从多种取值里选取(不小于两种)。
- Multi-label active learning: 在分类任务中,每个样本可以同时存在多个标签。
- Multi-task active learning: 多个任务需要被同时处理,比如同时进行两个分类任务,或同时进行一个分类和一个回归任务。
- Multi-domain active learning: 与多任务学习较为相似,多领域学习则是在不同的领域(数据分布/数据集)上学习相同的任务。
- Multi-view/modal active learning: 多视角或多模态学习中的样本可能会有不同形式的表征。比如不同角度拍摄的同一个物品,来源于同一视频的音轨和视轨等。
针对这些问题,主动学习方法一般都会有特定的适配和修改,仅仅使用简单场景上的方法可能不会有较好的表现。
2.3 与其他 AI 领域结合的问题场景
由于篇幅限制,主动学习与 AI 结合的领域和工作可以参见以下链接: AL Aids AI。
相较于之前提到的场景,AI 领域其实有不少更加复杂的问题。这些问题可能不能简单的用分类回归来表述,更多的时候是多种问题的结合。此类问题一般较为细致,定义也相对狭隘。针对这些具体问题,主动学习也有很多结合。 这些问题包括但不限于:
- Computer Vision (CV)
- Image Segmentation
- Object Detection
- Natural Language Processing (NLP)
- Sentence Classification
- Named Entity Recognition
- Domain adaptation/Transfer learning
- Metric learning/Pairwise comparison/Similarity learning
- One/Few/Zero-shot learning - Graph Processing
- etc.
3. 主动学习的技术角度的分类
在上一节中我们以问题为导向介绍了绝大多数可以使用主动学习来解决的问题,可以说涵盖了大部分最重要的主动学习的相关工作。 这一节的介绍并不是以问题为导向,而是从技术角度对现有方法进行分类。 我们选用了两个角度:
- 设计原理角度:希望读者对不同种策略有一定的认识。
- 适用模型角度:希望读者可以直接找到适用于自己模型的策略。
3.1 从设计原理上分类
这个角度是目前大部分 review/survey 的分类角度。 由于很多小问题中的相关文献较少,在我们的项目中,我们在对应的问题介绍下直接对相应方法作了简要分类。 本文中,我们的分类主要作用于最常见和最广泛的 Pool-based Classification 场景。 绝大多数著名的主动学习工作都是在此场景下进行的。 同样的,这里我们只简述设计原理,具体的文献列表参见我们项目中的这一章节。 在这里,我们把主动学习的设计原理(i.e.主动学习对样本的评估方法)分为五大类:
| 评估方法 | 简述 | 评论 |
|---|---|---|
| Informativeness | 一般来说指模型对选取样本取值的不确信程度 | 忽略了数据分布的影响 |
| Representativeness-impart | 考虑了选取样本是否可以对数据分布起到代表作用 | 通常来说和informativeness一起使用,此类方法和批选取方法可能会有重叠 |
| Expected Improvements | 考虑选取样本能为当前模型带来多少性能提升 | 此类评估通常较为耗时 |
| Learn to score | 不人为启发式地设计选取策略,而是学习一个选取策略 | |
| Others | 有一些工作较难分类到上述的类别中 |
此处我们也列出这几类方法之下的小类:
- Informativeness
- Uncertainty-based sampling
- Disagreement-based sampling
- Expected Improvements
- Representativeness-impart sampling
- Cluster-based sampling
- Density-based sampling
- Alignment-based sampling
- Expected loss on unlabeled data
- Learn to Score
- Others
此外,批选取的方法(batch active learning)也有众多研究,其与 representativeness-impart sampling 有一定的交叉,具体可以参阅以下链接: Batch mode
3.2 从适用模型上分类
很多种主动学习选取策略都标榜自己是全模型通用(model-free)的,但是实际使用中,他们可能仅仅适用于一个或一类模型(model-dependent)。 此处我们总结了一些 model-dependent 的策略在特定模型上的工作。 由于业界的模型实在是过于多样,此处我们仅归纳了几类常用模型,且工作并不一定很全,之后这个章节也会更新。 具体的文献列表请查阅我们项目中的这一章节。
这里我们仅列出一些我们总结到的模型:
- SVM/LR
- Bayesian/Probabilistic Models
- Gaussian Progress
- Decision Trees
- Neural Network
此外,如何设计适用于神经网络的主动学习策略和框架也是一个比较重要的问题。我们也对相关的深度主动学习进行了调研,详情请查阅以下链接: AL with Models
4. 将 AL 应用时的实际考虑
我们之前讨论的是主动学习可以应用于什么问题场景,本节我们讨论的是实际应用主动学习的时候可能会遇到什么技术问题。 具体的内容列表请查阅我们项目中的这一章节: Practical Considerations
简要来说,大部分的主动学习工作对数据,标注专家,问题规模等都是有着一般性的假设。 比如“在一个几千样本上的平衡分类问题中,可以通过询问一个准确率百分之百的标注专家来获得标注数据”。 但是这些假设在实际运用中可能并不总能保真,所以本节我们纳入了很多对实际问题的考虑。
具体的考虑如下:
- Data (imbalanced, biased, feature missing, etc.
- Oracles (multiple labeler, diverse labeler, etc.)
- Scale (large-scale)
- Workflow (cold start problem, stop criteria, etc.)
- Model training cost
- Query/feedback types
- Performance metric
- Robustness
- More assumptions
可以说在这些问题上的研究拉近了主动学习到实际运用的距离。
5. AL 的实际应用
主动学习已经是一个较为成熟的技术,已经有很多研究工作将其应用于不同学科和领域。 这里我们将其分为两部分:科学研究应用和工业界应用。 具体的文献列表请查阅以下链接: AL Applications
5.1 科学研究应用
目前的工作主要聚焦于以下几个学科:
- Biology
- Materials
- Astronomy
- Chemistry
- Math and Statistics
- Geology
- Experiment Design / Experimental Condition Selection
5.2 工业界应用
工业界应用相对较广泛,此处列举几个较为常用的领域,其他内容请参阅我们的项目。
- Remote Sensing
- Medical Research
- Drug Discovery
- Labeling System
- Spam Detection
- etc.
6. 相关资料
6.1 软件包
在github上已经有不少基于Python的主动学习软件包:
| Name | Languages | Author | Notes |
|---|---|---|---|
| AL playground | Python(scikit-learn, keras) | Abandoned | |
| modAL | Python(scikit-learn) | Tivadar Danka | Keep updating |
| libact | Python(scikit-learn) | NTU(Hsuan-Tien Lin group) | |
| ALiPy | Python(scikit-learn) | NUAA(Shengjun Huang) | Include MLAL |
| pytorch_active_learning | Python(pytorch) | Robert Monarch | Keep updating & include active transfer learning |
| DeepAL | Python(scikit-learn, pytorch) | Kuan-Hao Huang | Keep updating & deep neural networks |
| BaaL | Python(scikit-learn, pytorch) | ElementAI | Keep updating & bayesian active learning |
| lrtc | Python(scikit-learn, tensorflow) | IBM | Text classification |
| Small-text | Python(scikit-learn, pytorch) | Christopher Schröder | Text classification |
| DeepCore | Python(scikit-learn, pytorch) | Guo et al. | In the coreset selection formulation |
| PyRelationAL: A Library for Active Learning Research and Development | Python(scikit-learn, pytorch) | Scherer et al. | |
| DeepAL+ | Python(scikit-learn, pytorch) | Zhan | An extension for DeepAL |
6.2 Tutorials
之前也有一些关于主动学习的研讨班内容:
- active-learning-workshop: KDD 2018 Hands-on Tutorial: Active learning and transfer learning at scale with R and Python
- Active Learning from Theory to Practice: ICML 2019 Tutorial.
- Overview of Active Learning for Deep Learning: Jacob Gildenblat.
6.3 领域内研究学者
参见我们的项目,排名不分先后(有待补充)